Analysis of Big Dependent Data in Economics and Finance
Abstract:
Big data are common in many scientific fields and have attracted much research interest in machine learning, computer science, optimization and statistics. Econometrics and finance are no exception.
The goal of analyzing big data is to extract its useful information effectively and timely. In this talk, we introduce analysis of big dependent data by focusing on economics and finance.
We review methods available for analyzing big data and discuss their advantages and limitations. We compare the concepts of sparsity and parsimony in modeling, and emphasize the impact of serial dependence on methods developed for independent data.
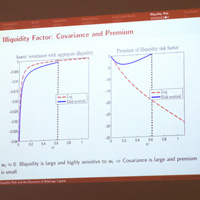
Examples are used to demonstrate the analysis. The methods discussed include (a) various penalized likelihood methods for statistical modeling such as LASSO regression and its extensions, (b) transformation to functional data for simplification, (c) tree-based methods for classification and prediction such as bagging, boosting, and random forests, (d) some methods for analyzing big dependent data.
The demonstration is carried out using the R software. Cross-validation (both leave-one-out and K folds) is used to select the penalty (or smoothing) parameter. If time permits, we further illustrate some applications.